ollama测试使用llama3 70b模型
1. 首先启动本地ollama 服务,如果不会,可以参考:https://www.forasp.cn/html/3146.html
2. 自动下载并运行模型
(1) 查看现有支持的模型列表 https://ollama.com/library
(2)选择下载并运行:在上述列表中选择 llama3
到最下面
Model variants
Instruct is fine-tuned for chat/dialogue use cases.
Example: ollama run llama3 ollama run llama3:70b
我们使用 70b 的模型
(3)开始下载运行
ollama run llama3:70b


我本地是 I3 12100+显卡3070 8G +64G内存,看下下面的资源使用。实际需要大于40G 内存
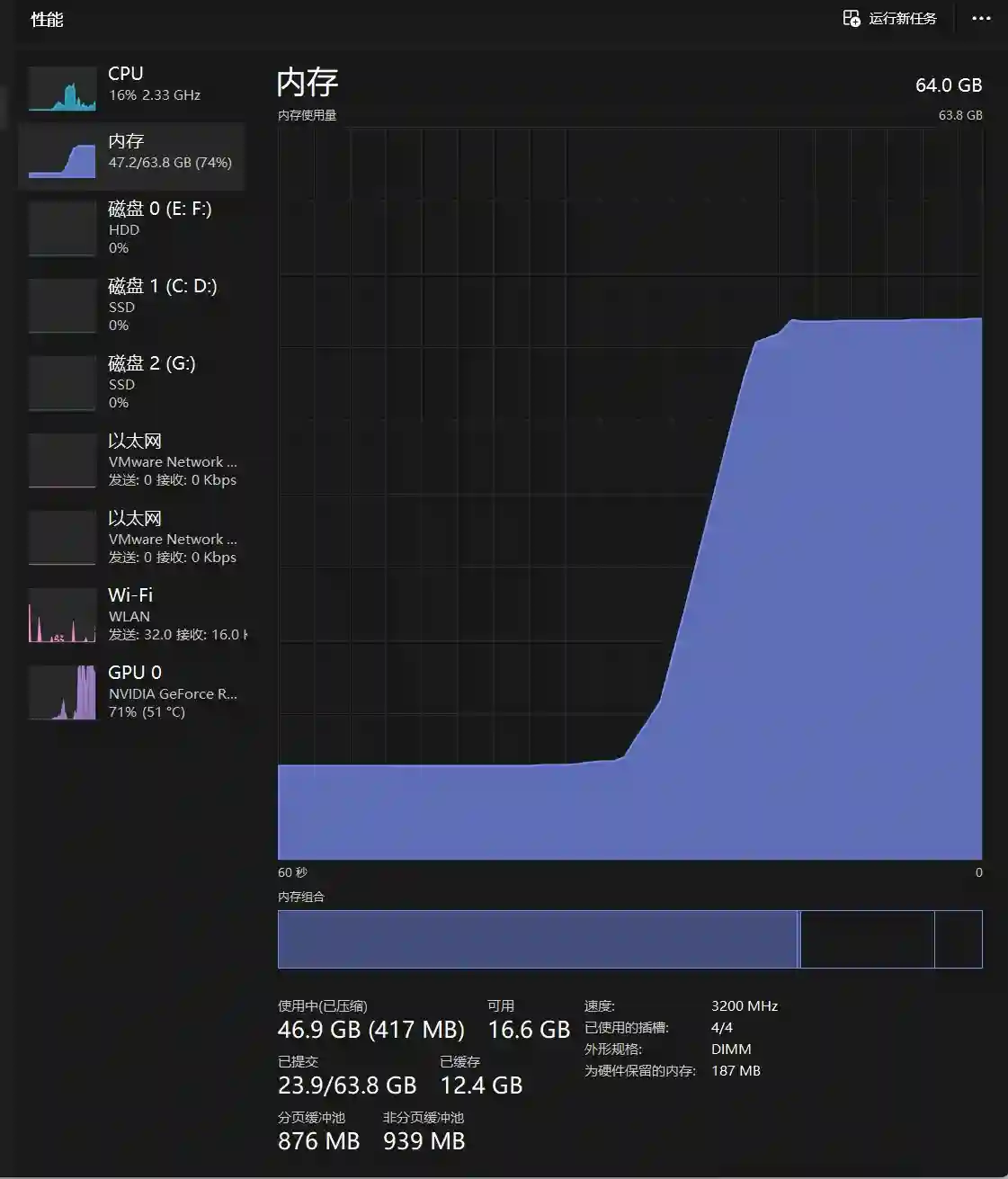

GPU使用情况、
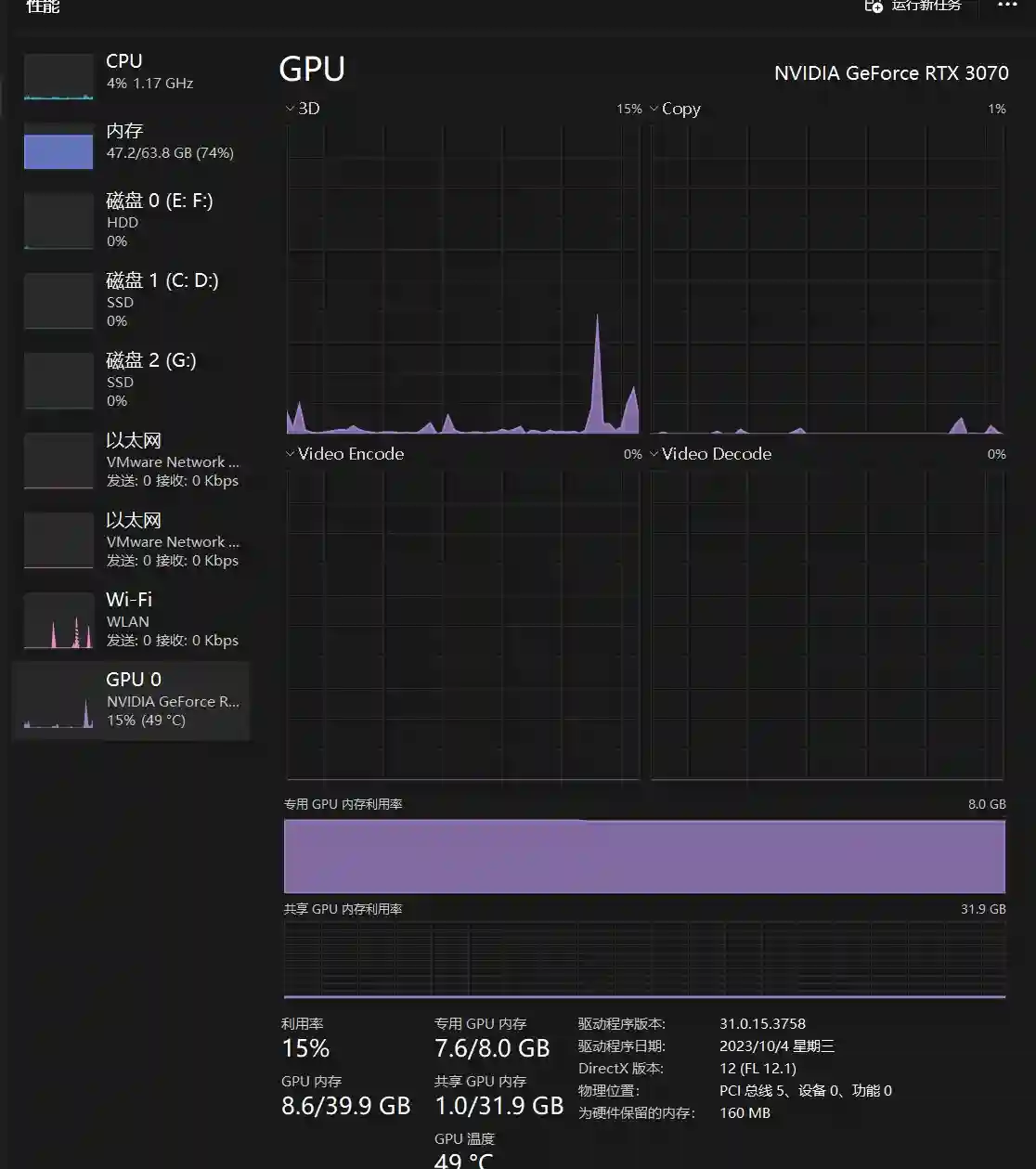
3. 测试服务
让它 用python 写一个贪吃蛇的游戏
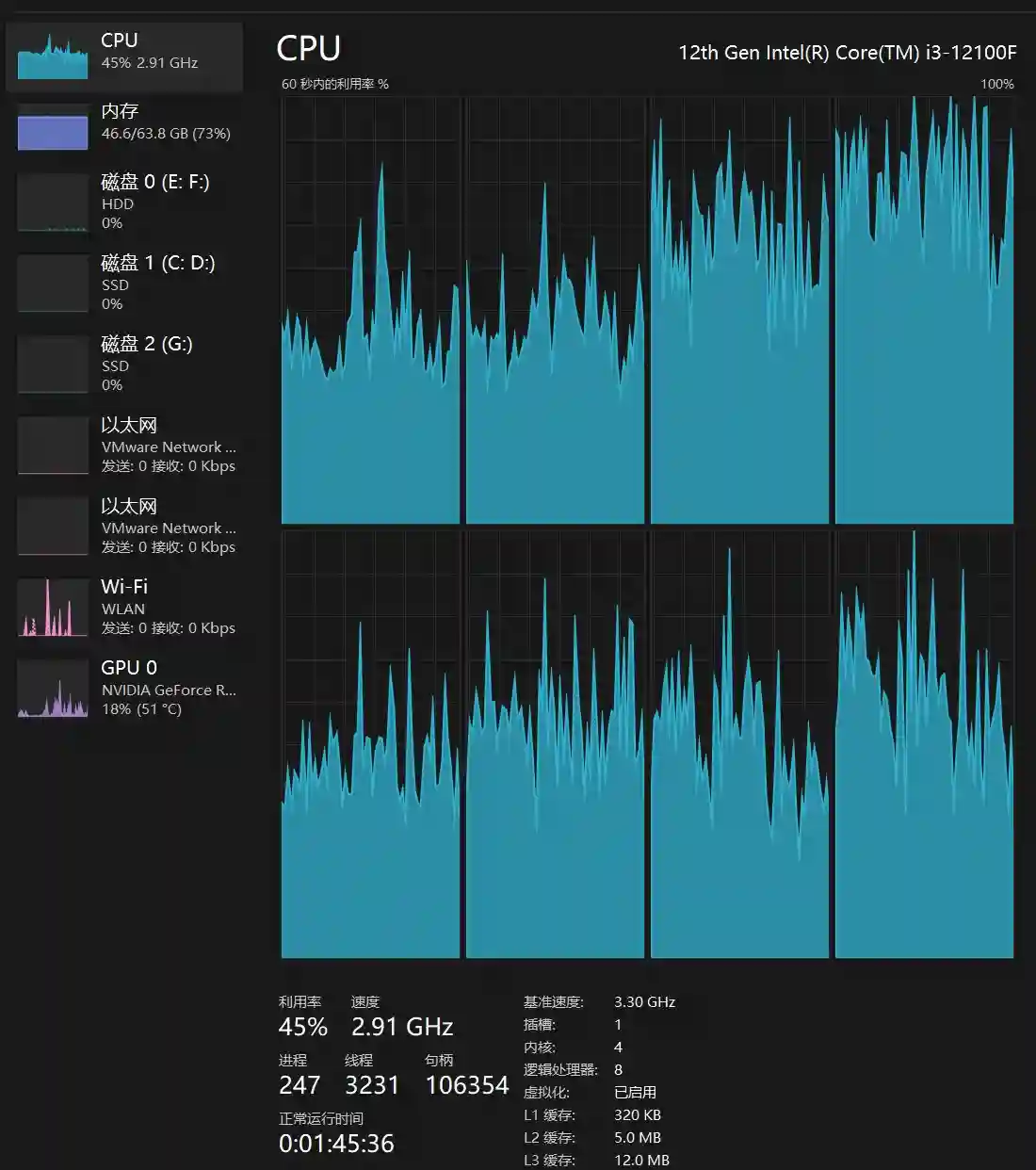

CPU 没有跑满,反应很慢,最后写出来是正确的。结果就不展示了。
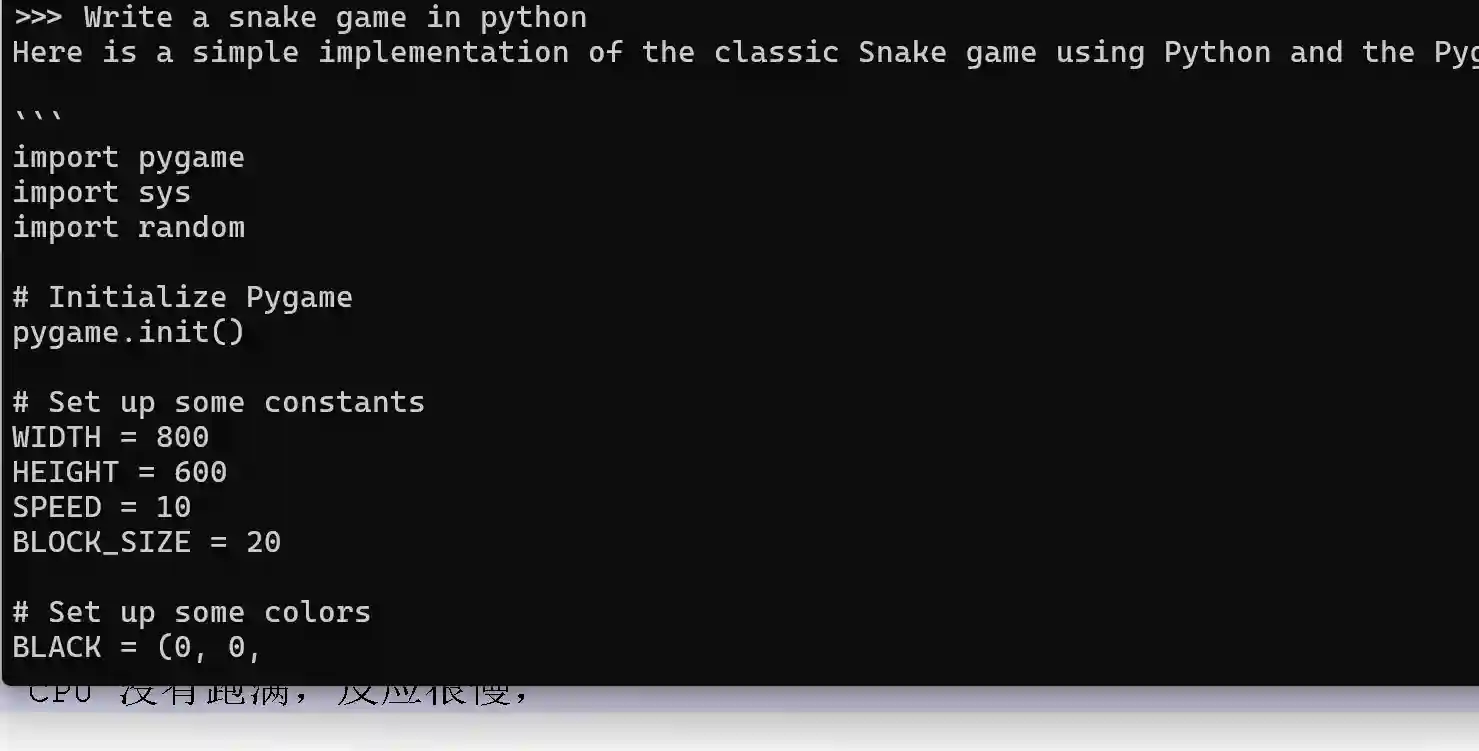
以上就是ollama 3 使用测试过程。 由于本地硬件性能原因比较慢,其它都很不错。
原文章%77w%77%2Ef%6F%72%61%73%70%2E%63n