linux 安装配置solr
Linux 2023/9/18 21:41:08 点击:不统计
<本文原载于www.forasp.cn>
1. 首先确定已经安装了java 环境。运行
$ java -version
openjdk version "1.8.0_372"
OpenJDK Runtime Environment (build 1.8.0_372-b07)
OpenJDK 64-Bit Server VM (build 25.372-b07, mixed mode)
2. 下载 solr 源代码,这里我们用阿里云的镜像
https://mirrors.aliyun.com/apache/lucene/solr/8.11.2/?spm=a2c6h.25603864.0.0.4cab3674xpOcDQ
下载8.11.2版本文件:solr-8.11.2.tgz
下载后解压到:/usr/local/solr-8.11.2/
3. 测试启动solr (目前无其他配置)
$ cd /usr/local/solr-8.11.2/ (下命令都一样在该文件夹)
$ ./bin/solr start -force
Warning: Available entropy is low. As a result, use of the UUIDField, SSL, or any other features that require
RNG might not work properly. To check for the amount of available entropy, use 'cat /proc/sys/kernel/random/entropy_avail'.
Waiting up to 180 seconds to see Solr running on port 8983 [|]
Started Solr server on port 8983 (pid=749360). Happy searching!
然后去访问 8983端口 如果是本地 http://localhost:8983 你会看到下面界面
如果是线上,则访问solr : http://ip:8983
停止命令
$ ./bin/solr stop -all
注意: 如果是阿里云,需要开放对应端口
4. 创建一个索引库 forasp (这个是个名称自定义)
(1)方法1 ,通过命令创建库
$ ./bin/solr create -c forasp
....
Created new core 'forasp'
(2)方法2 手动创建库
$ mkdir server/solr/forasp
复制配置文件
$ cp example/example-DIH/solr/solr ./server/solr/forasp
然后启动solr 你会看到你创建的库。如下图

5. 配置建立中文分词类库,实现中文分词
(1)下载 中文分词工具,根据自己solr 版本选择,地址
https://search.maven.org/ 搜索ik-analyzer 找到 IK-Analyzer for 7-8 就适配 solr 8.11.2
下载地址
https://repo1.maven.org/maven2/com/github/magese/ik-analyzer/8.5.0/ik-analyzer-8.5.0.jar
放到 server/solr-webapp/webapp/WEB-INF/lib
(2)编辑 索引库forasp 配置文件,新增对应字段。编辑 server/solr/forasp/conf/managed-schema 将下面代码添加到</schema> 结束之前
<field name="chinese_all" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<!--下面的定义字段与上面不同的是 type 为text_ik_smart,详细区别见下面-->
<field name="chinese_smart" type="text_ik_smart" indexed="true" stored="true" multiValued="false"/>
<!--字段type 类型定义,这里定义text_ik ,索引和查询都是用IK分词-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!--字段type 类型定义,这里定义text_ik ,索引和查询都不分词,是全匹配搜索类似于mysql like,更严谨。定义useSmart =true -->
<fieldType name="text_ik_smart" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema>
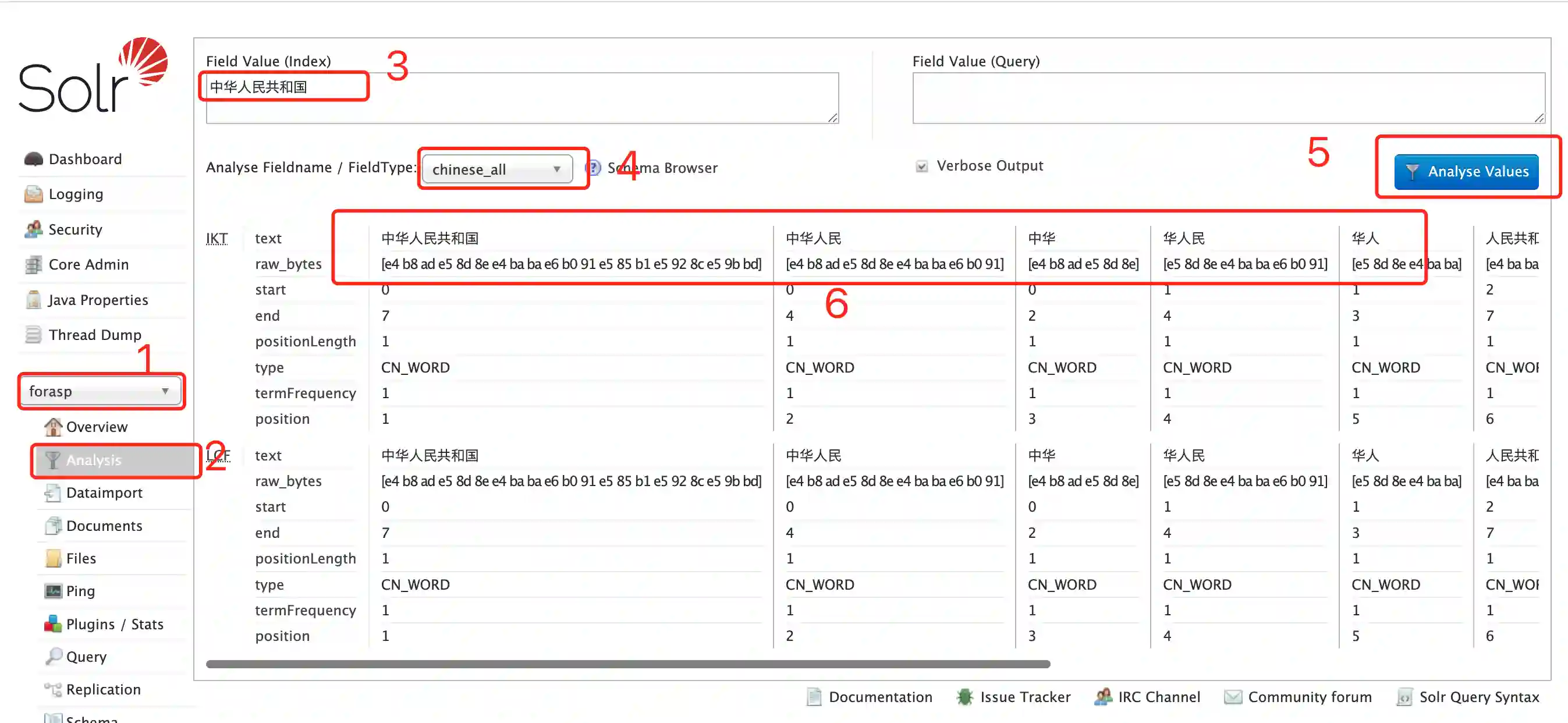
(3)重启solr 测试分词工具,访问solr 界面,选择forasp 库,选择Analysis ,输入“中华人民共和国”进行分词,fieldType 选择上面定义的chinese_all,点击分析结果如下图:

6. 配置创建 mysql数据库内容导入功能
(1)复制导入jar 包到web lib下 (操作目录仍然是 /usr/local/Cellar/solr/8.11.2/)
$ cp ./dist/solr-dataimporthandler-* server/solr-webapp/webapp/WEB-INF/lib
(2)下载mysql 版本对应的java 连接类jar 包,我是mysql5.7 下载的是5.1.49
https://mvnrepository.com/artifact/mysql/mysql-connector-java
下载后放到 server/solr-webapp/webapp/WEB-INF/lib
(3)编辑forasp 索引库 配置文件 ,追加数据源配置
$ vim server/solr/forasp/conf/solrconfig.xml
在结尾 </config> 前新增加如下代码 (dataimport 必须小写)
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">dataconfig.xml</str> <!--这里是数据库配置文件-->
</lst>
</requestHandler>
(4)新增数据库配置文件 dataconfig.xml ,原来没有该文件,这里是新增
$ vim server/solr/forasp/conf/dataconfig.xml
#添加内容如下
<?xml version="1.0" encoding="utf-8"?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver" 这个是对应mysql 版本的java 数据库连接
url="jdbc:mysql://localhost:3306/databasename"
user="root"
password="password" />
<document>
<entity name="searcheindexname" query="select log_ID,log_Title from T_post">
<field column="log_ID" name="id"/> id 是默认有的
<field column="log_Title" name="chinese_all"/> #这里的column 是我们源数据库字段
# name 是 搜索索引字段field字段名称,可以自定义,但与上面定义的名称要一致
</entity>
</document>
</dataConfig>
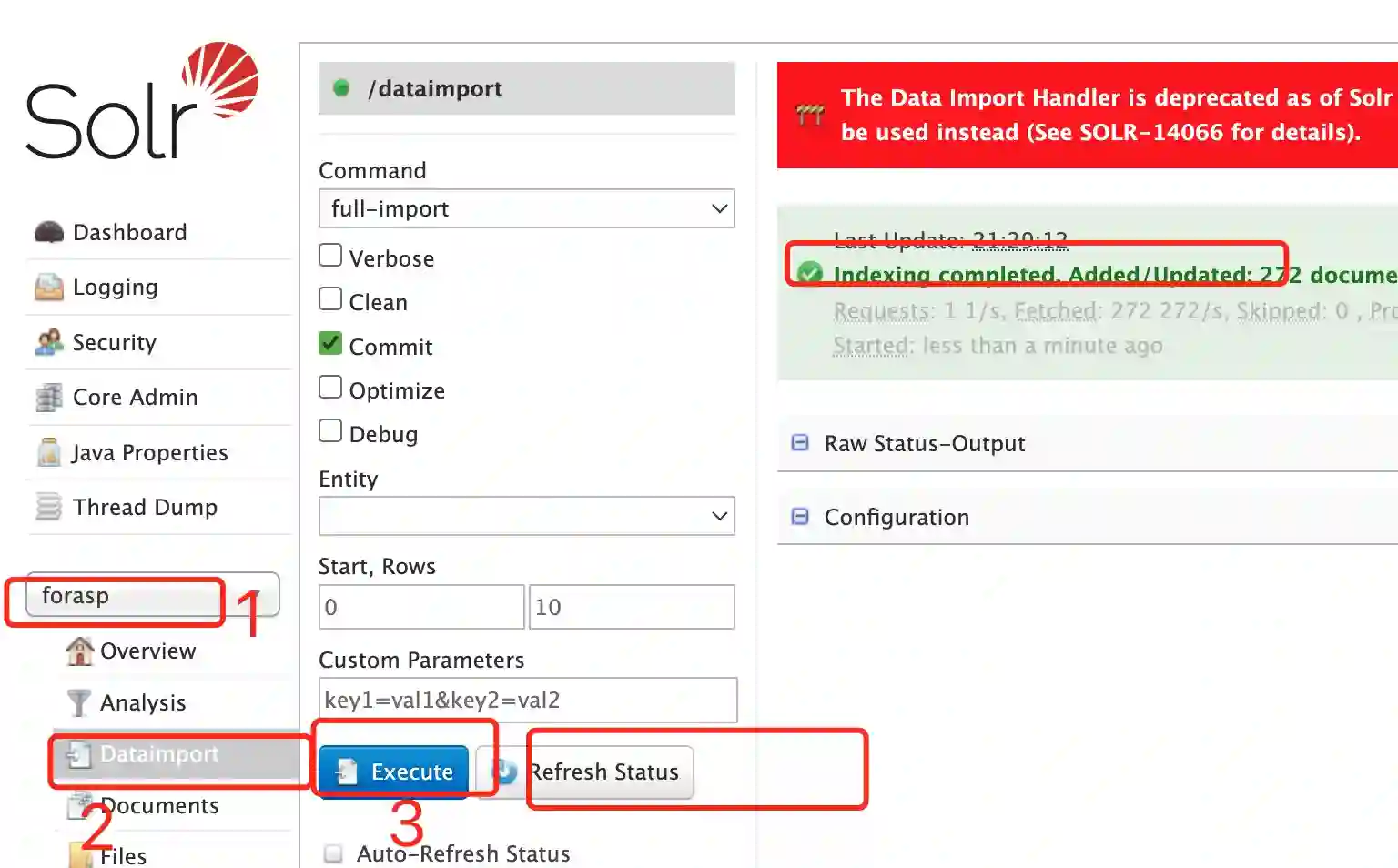
(5) 重启solr ,选择 forasp 索引,点击Dataimport ,点击执行试试,结果如下:

(6)测试solr 搜索功能,如下图,搜索字段,就是我们定义和存储的字段chinese_all, 内容:方法
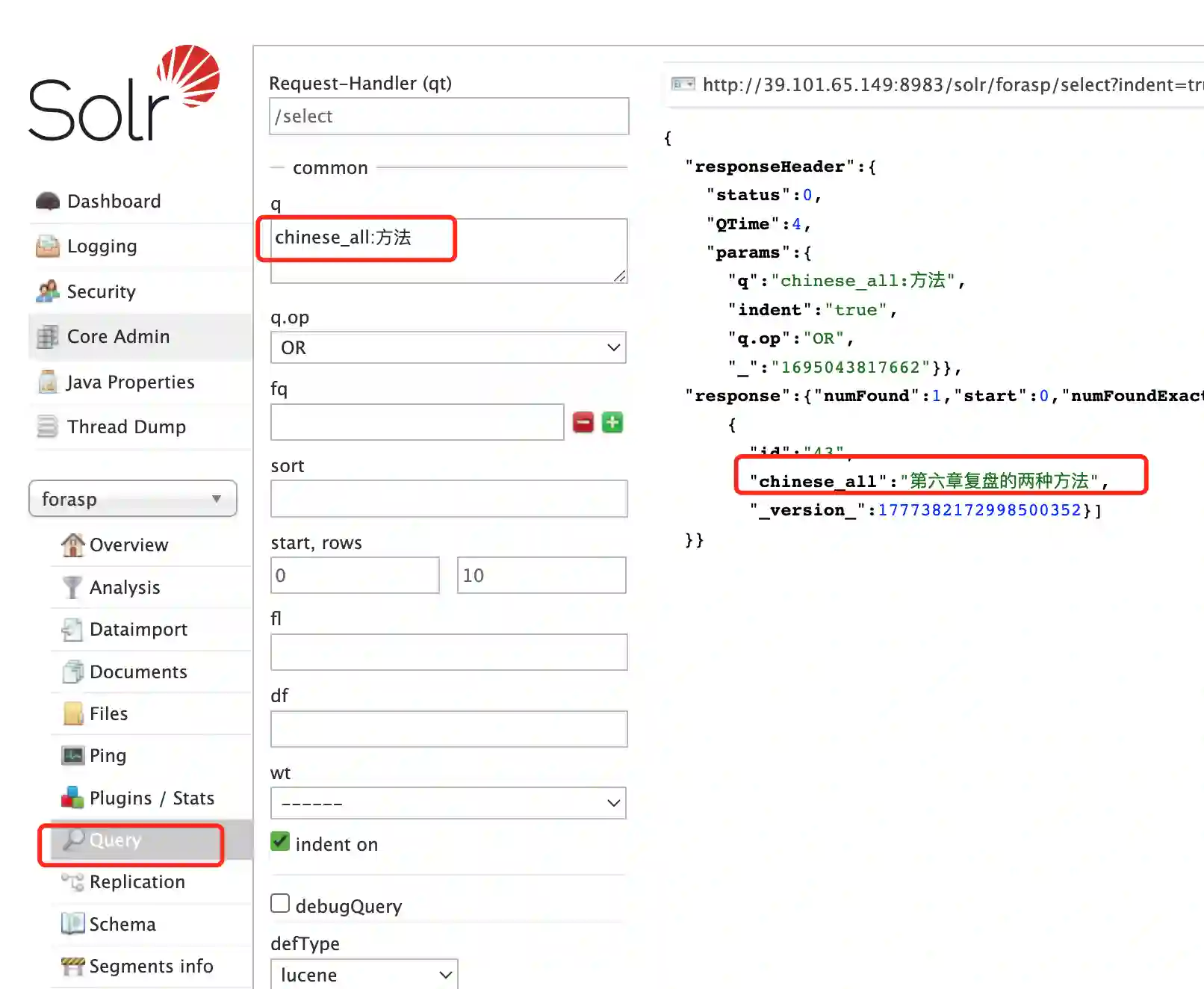
以上就配置完毕了,下个我们说安全配置。
<%77w%77%2Ef%6F%72p%73%70%2Ec%6E>
・上一篇:mac安装Solr >> ・下一篇: solr设置账号密码solr修改账号密码 >>